So, I observed the UI was talking around 2 minutes to load. I was wondering why? Then I found there are couple of CPU bound tasks involving complex calculations in the code like evaluate_investment for long term decisions and making short term decisions. I will give example code to illustrate this.
Offloading Synchronous Tasks to different threads
Ideally to make the system async we can use create_task and gather the result. But this will work only when the passed function is async. create_task() allows asynchronous functions to run concurrently within the event loop, which is ideal for non-blocking I/O operations. There is an example in the code where I am using this concept.
async def load_additional_data(request):
risk_management_task = asyncio.create_task(retrieve_risk_management_data_async())
market_returns_task = asyncio.create_task(market_returns_async())
try:
all_ticker_data, market_returns_dict = await asyncio.gather(risk_management_task, market_returns_task)
logger.info("Risk management and market returns data fetched successfully")
except Exception as e:
logger.error(f"Error fetching risk management or market returns data: {e}")
all_ticker_data = {}
market_returns_dict = {}
# Process graphs asynchronously
try:
graphs = await process_graphs(all_ticker_data, market_returns_dict)
logger.info("Graphs processed successfully")
except Exception as e:
logger.error(f"Error processing graphs: {e}")
graphs = {}
logger.debug(f"graphs--------------------> {graphs}")
# Return the additional data as JSON
return JsonResponse({
'graphs': graphs,
})But in case you have sync functions and you cannot make it async because you need some value to be present for executing the next line then you use to_thread. But it’s not as scalable for handling a large number of concurrent operations because each to_thread() call involves creating a separate thread. So have use it for calculative function which dont depend on any network request.
All the line marked as bold are huge cpu bound sub tasks involving fetching of data from third party and making calculation on them . This data ranges last 5 years data so just imagine how huge it could be.
async def analyze_group_of_symbols_async(symbols):
results = {}
logger.info(f"Starting analysis for symbols: {symbols}")
market_growth_symbol = 'SPY'
market_growth = await get_market_growth_async(market_growth_symbol)
logger.info(f"Market growth data fetched for {market_growth_symbol}")
if market_growth is not None:
avg_market_growth = market_growth['Market_Growth'].mean()
logger.info(f"Average Market Growth: {avg_market_growth:.2f}")
else:
logger.warning("Market growth analysis failed.")
return {}
thresholds = {
'max_debt_to_equity': 2.0,
'min_roe': 0.15,
'min_gross_margin': 0.40
}
if avg_market_growth < 1.0:
thresholds['min_roe'] += 0.05
thresholds['min_gross_margin'] += 0.05
elif avg_market_growth > 1.1:
thresholds['min_roe'] -= 0.05
thresholds['min_gross_margin'] -= 0.05
for symbol in symbols:
try:
logger.info(f"Fetching financial data for symbol: {symbol}")
financial_data = await fetch_financial_data_finnhub_async(symbol)
financial_ratios = calculate_financial_ratios(financial_data)
long_term_decision = await asyncio.to_thread(evaluate_investment, symbol, financial_data, financial_ratios, thresholds)
logger.info(f"Financial analysis completed for symbol: {symbol}")
end_date = datetime.now().strftime('%Y-%m-%d')
start_date = (datetime.now() - timedelta(days=5*365)).strftime('%Y-%m-%d')
try:
logger.info(f"Fetching price data for symbol: {symbol}")
price_data_raw = await asyncio.to_thread(yf.download, symbol, start=start_date, end=end_date)
price_data = price_data_raw['Adj Close']
except KeyError as e:
logger.error(f"KeyError: {e} for ticker {symbol}. Data might not be available.")
continue
except Exception as e:
logger.error(f"Failed to fetch price data for symbol {symbol}: {str(e)}")
continue
macd, signal_line = await asyncio.to_thread(calculate_macd, price_data)
moving_average = await asyncio.to_thread(np.mean, price_data)
rsi = 75 # Example RSI value
# Convert NumPy arrays to lists for JSON serialization
results[symbol] = convert_to_json_serializable({
'short_term_decision': await asyncio.to_thread(make_short_term_decision, price_data, rsi, macd, signal_line, moving_average),
'long_term_decision': long_term_decision,
'price_data': price_data.tolist(), # Convert to list for JSON serialization
'rsi': rsi,
'macd': macd.tolist() if isinstance(macd, np.ndarray) else macd,
'moving_average': float(moving_average), # Ensure this is a float, not a NumPy type
'financial_data': financial_data # Ensure financial_data is JSON serializable
})
except Exception as e:
logger.error(f"Failed to analyze symbol {symbol}: {str(e)}")
continue
logger.info(f"Analysis complete for symbols: {symbols}")
return resultsSo, in the main thread this function call is placed like the below:
async def compute_final_context(symbols, scenarios):
# Start the analysis for the symbols asynchronously
try:
decision_results = await analyze_group_of_symbols_async(symbols)
logger.info("Decision results fetched successfully")
except Exception as e:
logger.error(f"Error fetching decision results: {e}")
decision_results = {}
# Generate the HTML output and graph data
try:
html_entries, graph_data = get_decision_html_and_graphs(decision_results)
logger.info("HTML and graph data generated successfully")
except Exception as e:
logger.error(f"Error generating HTML and graph data: {e}")
html_entries = []
graph_data = {}
return {
'html_entries': html_entries,
'loading': False,
'scenarios': scenarios,
'graphs': graph_data
}So, in usual flow, until the decision_results are available, the execution will not proceed and the call from UI would hang and the UI becomes unresponsive. So to avoid that I have offloaded some of the functions to a different thread in analyze_group_of_symbols_async function so that until the calculation happens the next part of the code executes.
And when the results is available it is propagates to the calling function. It return a coroutine so we have to await to make it back to desired structure. This is one aspect of thread execution in python which is really interesting.
Making concurrent requests to external service
Next I will talk about how can we make concurrent network requests. Basically we want to pass array of entities and we want the system to calculate the results on each element of the array at once and return the results. Fetching the data from network requests is a very good example for this.
def retrieve_risk_management_data():
base_url = "http://realtimequotesproducer:8003/quotes_producer/"
tickers = ['AAPL', 'MSFT', 'GOOGL', 'AMZN', 'TSLA']
urls = []
for ticker in tickers:
ticker_urls = {
"daily_returns": f"{base_url}daily-returns/{ticker}/",
"portfolio_returns": f"{base_url}portfolio-returns/",
"var": f"{base_url}var/"
}
urls.append(ticker_urls)
logger.info(f"Checking ticker_urls {ticker_urls}")
all_ticker_data = {}
for ticker_urls in urls:
ticker = ticker_urls["daily_returns"].split("/")[-2] # Extract ticker from URL
all_ticker_data[ticker] = fetch_ticker_data(ticker_urls)
return all_ticker_data
def fetch_ticker_data(ticker_urls):
results = {}
with ThreadPoolExecutor(max_workers=3) as executor:
future_to_url = {executor.submit(fetch_api_data, url): key for key, url in ticker_urls.items()}
for future in as_completed(future_to_url):
key = future_to_url[future]
try:
data = future.result()
results[key] = data
except Exception as exc:
print(f"{ticker_urls[key]} generated an exception: {exc}")
return resultsAs we can see there are three URLS and a array of 5 symbols, we want data for three url for those 5 symbols. If we go by usual approach then we have to iterate the 5 symbols and fetch the three urls data which could be really time consuming.
So there is the implementation for threadpool, which creates a thread pool that can execute up to 3 threads concurrently.
for ticker in tickers:
ticker_urls = {
"daily_returns": f"{base_url}daily-returns/{ticker}/",
"portfolio_returns": f"{base_url}portfolio-returns/",
"var": f"{base_url}var/"
}
urls.append(ticker_urls)
logger.info(f"Checking ticker_urls {ticker_urls}")This code would give me 5 * 3 urls.
future_to_url = {executor.submit(fetch_api_data, url): key for key, url in ticker_urls.items()}This code would submit the urls to the threadpool for calculations.
for future in as_completed(future_to_url):
key = future_to_url[future]
try:
data = future.result()
results[key] = data
except Exception as exc:
print(f"{ticker_urls[key]} generated an exception: {exc}")
This code on gathering all the data resolves the results and returns. Below is the psudocode.
Function fetch_ticker_data(ticker_urls):
Initialize an empty dictionary called results
Create a ThreadPoolExecutor with a maximum of 3 workers
Create a dictionary called future_to_url:
For each key, url in ticker_urls:
Submit a task to the ThreadPoolExecutor to fetch data from url
Map the resulting Future object to the key in future_to_url
For each completed Future object in future_to_url:
Get the corresponding key from future_to_url
Try to retrieve the result of the Future:
Store the result in results with the key
If an exception occurs:
Print the exception and the corresponding URL
Return resultsfuture_to_url = {
<Future at 0x7f8c1a7b9fd0 state=running>: "daily_returns",
<Future at 0x7f8c1a7c10d0 state=running>: "portfolio_returns",
<Future at 0x7f8c1a7c11f0 state=running>: "var"
}for future in as_completed(future_to_url):
key = future_to_url[future]
try:
data = future.result()
results[key] = data
except Exception as exc:
print(f"{ticker_urls[key]} generated an exception: {exc}")Here I am mapping the key and getting the result.
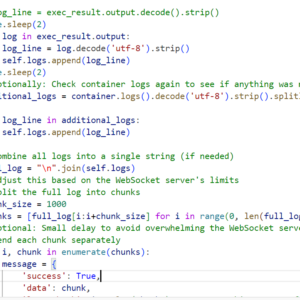
Here is a illustration of how the app is working now.

Great insights! For those looking to blend gaming with strategy, check out the AI-driven features at JiliOK Link-it’s a fresh take on smart play.