The first term that comes to mind when you think about decision tree in ML is “supervised learning“.
So, what is supervised learning in ML? It is the situation where the machine has labelled data as input, it is used to the train the model so that it can predict the output.
On the contrary, unsupervised learning in ML is a situation where no information about data is present like clustering, segmentations.
So circling back to supervised learning, it is divided into two categories- classification problems and regression problems. And a decision tree is a supervised learning algorithm that is used for classification and regression modeling.
So, what is a decision tree?
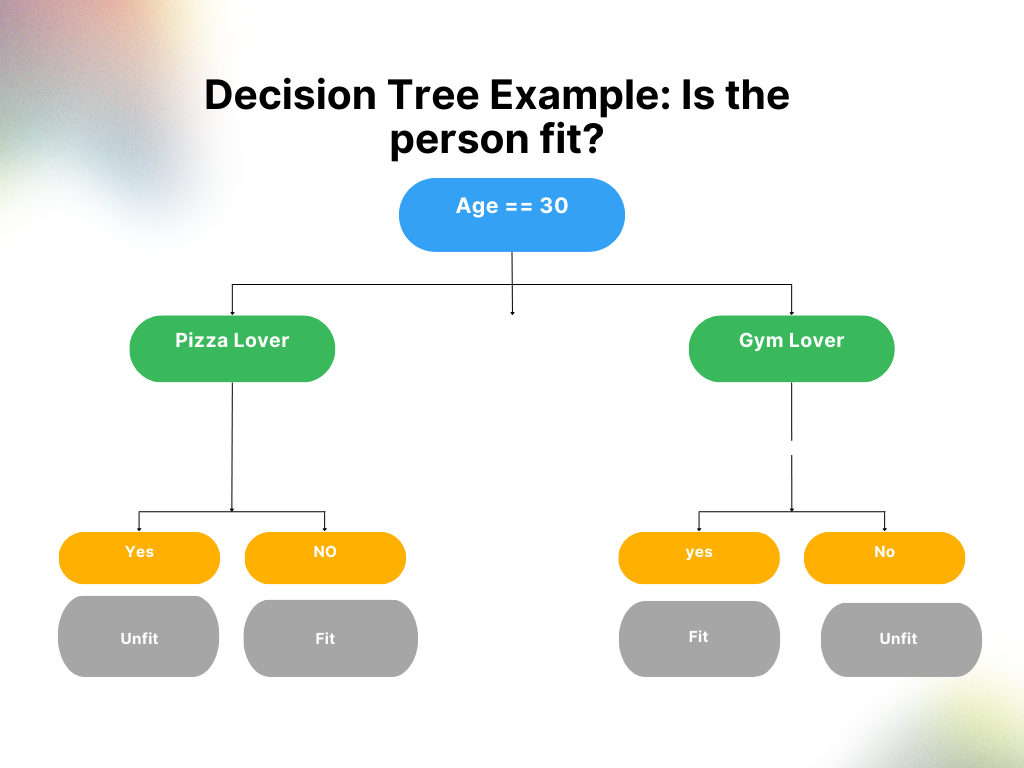
If you see the above example, you would see in layman’s terms its a simple if else solution to find whether a person is fit or not. Decision tree is nothing but a set of if else condition checks.
Types of decision trees in Machine Learning
For classification Trees, it is simple a yes or no type of situation and regression trees it how many and how much like how much will be the salary of data scientists in 2025.
Decision Tree Terminologies
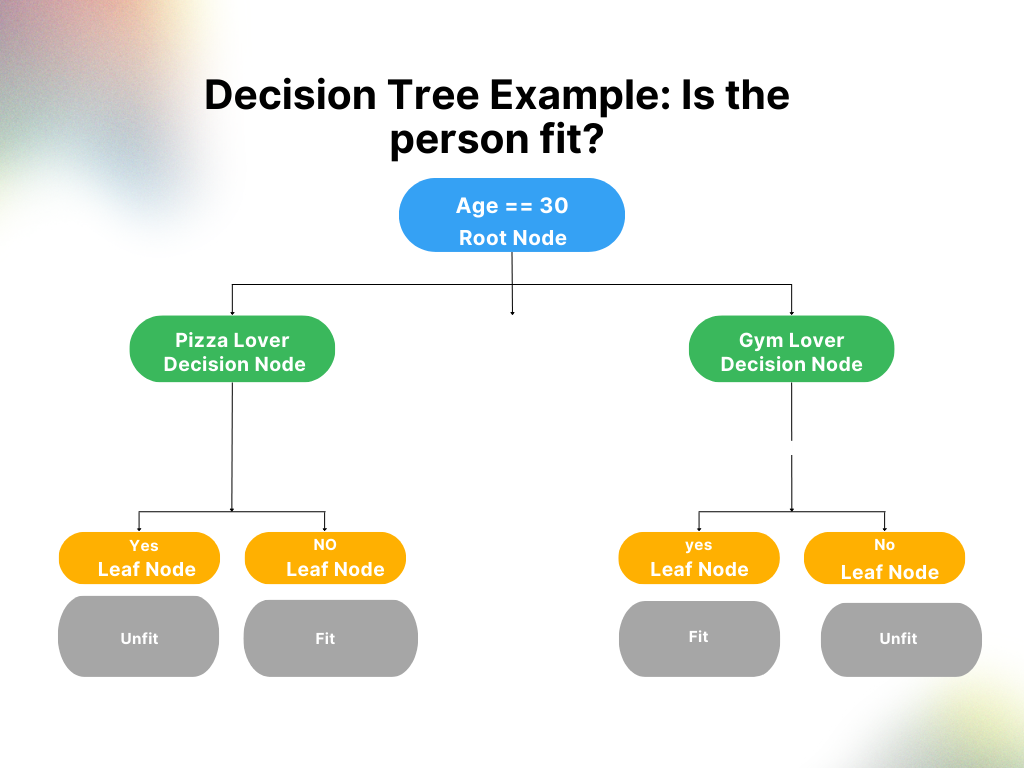
- Root node: The topmost node of a decision tree that represents the entire message or decision
- Decision (or internal) node: A node within a decision tree where the prior node branches into two or more variables
- Leaf (or terminal) node: The leaf node is also called the external node or terminal node, which means it has no child—it’s the last node in the decision tree and furthest from the root node
- Splitting: The process of dividing a node into two or more nodes. It’s the part at which the decision branches into variables
- Pruning: The opposite of splitting, the process of going through and reducing the tree to only the most important nodes or outcomes
Let’s understand the decision tree more comprehensively.
Why do you think we are only checking if the person is a pizza lover or a gym lover.
There is a concept of entropy in machine learning which measures the degree of disorder. So, if we see entropy we will split and this parameter is low we will conclude our prediction- if it is a yes or no.
So, while splitting the decision tree we are actually decreasing the degree of disorders to get the prediction. In the above case, we are getting a set of conclusions of whether the person is fit or not.
So, how do you find if there is high or low entropy?
Suppose I have 30 points for winning a competition and you have 29.5 points. In this case, it is very uncertain to tell who wins. so that how you measure the entropy.
In our case, we will decide about the entropy of how many Yes’s or No’s we have at the leaf node.
In decision tree, we need to focus on making the heterogeneity of the leaf node as less as possible to balance the entropy
Mathematically, we can calculate entropy using the below formula.
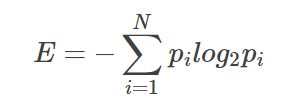
where pi is the probability of randomly selecting an example in class of i and N is the number of classes in the data set
Suppose, we have a dataset where we have images of dogs, cats, humans in a dataset. These are the classes.
In one of the observation, we have 16 dogs, 20 cats, and 2 humans images. So, our entropy becomes-
-(16/38 log2 (16/38)+ 20/38 log2 (20/38) + 2/38 log2 (2/38)) =
0.371
Now, using the same formula we can calculate the uncertainty as 0 when we have only dogs in the observation which means it does not have any impurity at all. It can be inferenced that is not an ideal data set, whereas if the data set has equal number of observations then it’s entropy is 1 which means its ideal dataset.
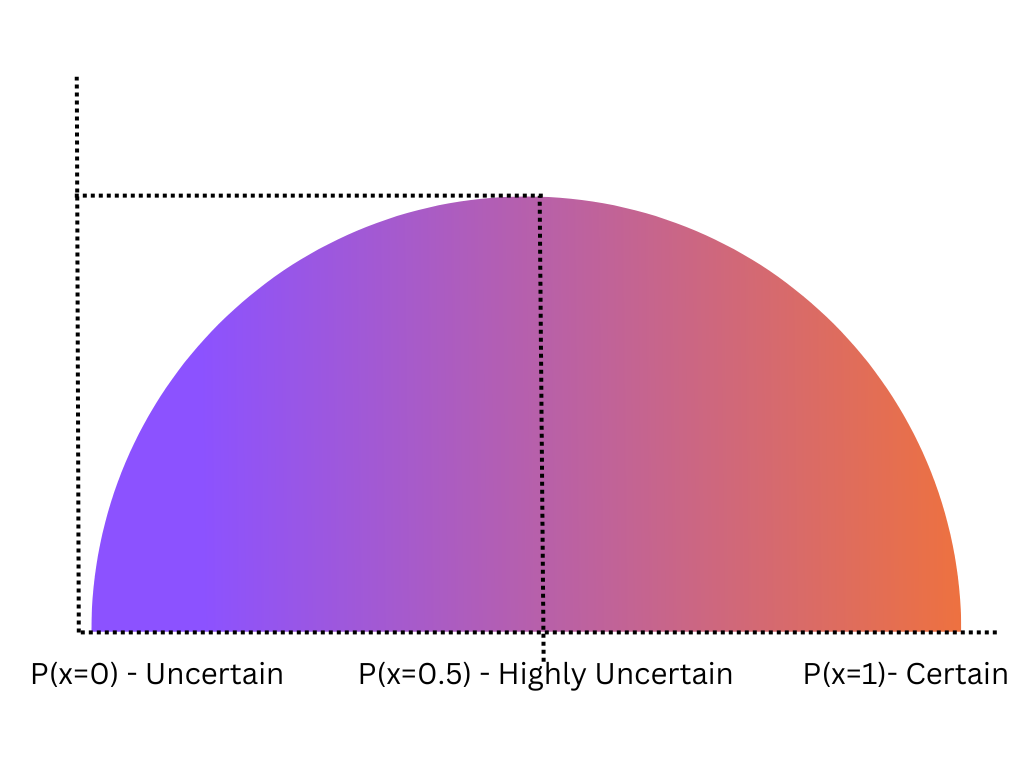
From the above graphs, we can conclude that our entropy is high as we have imbalanced dataset. In our case, with the first example, we have two yes and two no, thereby we can understand that we have highest uncertainty of whether the person is fit or not.
The first thing that comes to mind is where do i start splitting, for that we need to have some entropy information about the node.
To get the information, first we have to decide the root node which is the parent node and all other nodes under it as child nodes. And then we can find the difference of entropies of the root and child node to gain the information out of it and decide the quality of split.
But how do you decide the root node. So, we need to find out which node or feature has highest information gain and make it as root node.
A branch with an entropy of zero is a leaf node is highly uncertain so we need to split that up to decrease the uncertainty
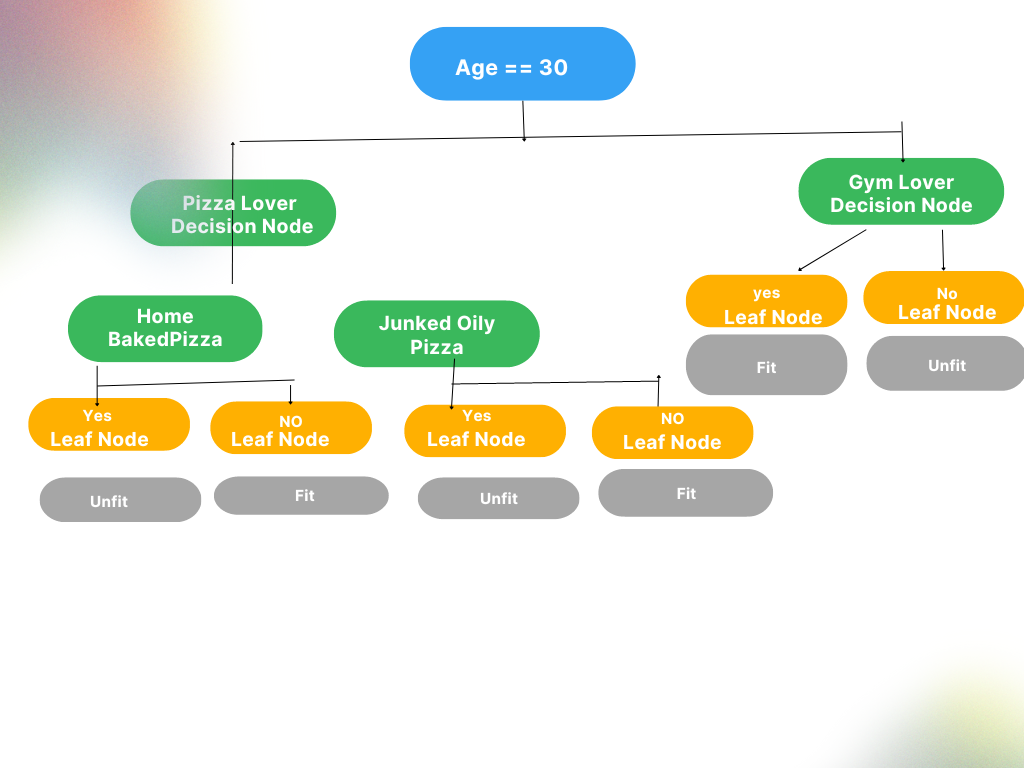
Now if I further split the left node of the tree of the above example and try to find out which could be a leaf node.

As here we can see that after splitting we get 3 Nos and 4 Yes. And the above entropy of the age node, as the entropy is nearing to zero the age node could be further split to get a majority of either yes or no.
Now once we have our leaf node we can find out how much is the information which is simply
Entropy(parent node) – Entropy(weighted average of entropy of each child node)
Information Grain = Entropy(Age Node) – (Entropy ( Child node1) + Entropy(Child node 2))
So, the method is simple:
- Start with a feature
- Calculate the entropy of that node
- If entropy is nearly or zero then that needs to be split
- Another of determining if it needs to be split is by looking at the yes and no at the leaf no
- If the No’s or Yes’s are not in majority then we need to split
The Overfitting Problem
As the tree grows, we have this overfitting problem. Overfitting is when a model completely fits the training data and struggles or fails to generalize the testing data. This happens when the model memorizes noise in the training data and fails to pick up essential patterns which can help them with the test data.
Pruning To Avoid Overfitting Problems
Theoretically, we got two kinds of techniques – Pre-pruning and Post-pruning.
Pre-pruning involves:
- Tuning the hyperparameters prior to the training pipeline
- Stops the tree-building process to avoid producing leaves with small samples
- Monitor the cross validation error in each stage of split
- Using parameters like
max_depth,min_samples_leaf, andmin_samples_splitfor early stopping
Post-pruning involves:
- Once the model grows to its full depth, tree branches are removed
- Compute the ccp_alphas value using
cost_complexity_pruning_path() - Train your Decision Tree model with different
ccp_alphasvalues and compute train and test performance scores - Plot the train and test scores for each value of
ccp_alphasvalues.
Programmatic Approach for reducing overfitting
Implementing Post-Pruning with Python’s sci-kit learn Package
To begin with, you can have your data set in here.
Watch the full video to get into the coding part